
This is part 4 of the Python integration in Power BI series. We are going to explore sourcing data from SQL Server (including Azure SQL DB). If you have been following the series, you would be familiar with the the basics of Pandas dataframes. You saw how easy it is to load data from a CSV file into a dataframe. Loading data from SQL Server is just as easy … but the hard work is setting up database connection strings.
This post will cover how to connect to SQL Server with a library called SQLAlchemy, and how to load data from SQL Server into a Pandas dataframe. We cover a few other things along the way i.e. using Windows environment variables, multi-line strings and working with string parameters.
Protecting sensitive information
In the previous post we worked with the os (operating system library) to access files. We will use the os library again, but this time to protect sensitive information. During the development process I like to keep keys, passwords, server names, etc outside of the script in a place that is not too easy to access. I store this info in User Environment Variables so that are only accessible to me. (Any other ideas to protect sensitive info welcome).
The os library has a getenv (get environment variable) method. We retrieve the value from the environment variable and assign it to a Python variable as follows:

Here you can see that two values are read from the environment variables and we see that sqldb has a value ‘Sandbox’. In this way we ensure that our Python scripts don’t store sensitive information, but will still run successfully in our development environment. If you have problems with the environment variables, just use plain text for now.
SQLAlchemy connection strings
SQLAlchemy is quite sophisticated, but we will using it in a fairly limited way. The “engine” or connection is covered in the documentation, but rarely will we have a standard or basic connection. Most of the time we will have a non-standard connection, in which case we have to pass the connection parameters in a connection string. SQLAlchemy expects this string in URL format.
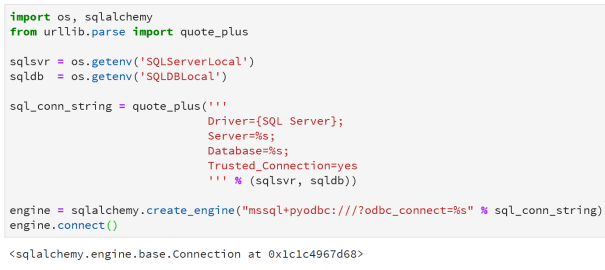
We will start by connecting to a SQL instance on a local machine. First we add the sqlalchemy library to our script. Then we store the connection string in a variable. 
To convert the connection string to URL format, we make use of the urllib library. Here we use the quote_plus method to convert spaces and special characters to URL format.

Maintaining connection strings in the above format is error prone and cumbersome. Python allows multi-line strings through the use of triple quotes. This can be either single quotes or double quotes.

Now we want to include the variables we created earlier. We are not going to construct the string from parts using concatenation. We are rather going to use the % placeholder for parameters in the string. We are only working with strings, so we will use %s as the placeholder. Note that they are interpreted in sequence.

Establishing a connection to SQL Server
We use the SQLAlchemy create_engine method to create an engine object that allows us to interact with the database e.g. the interaction could be as basic as establishing a query connection.
By adding an echo parameter to the create_engine method, we get more connection info.
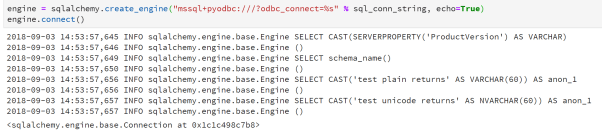
Only turn echo on if you are troubleshooting, otherwise its just a lot of noise.
Loading SQL results to a dataframe
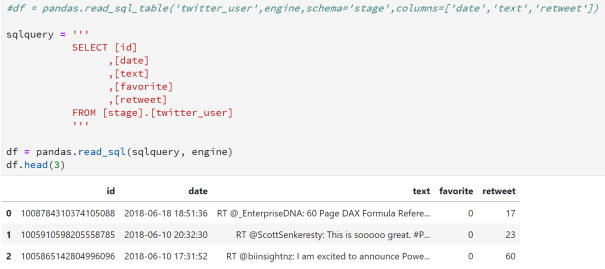
This is the easy part. We have a choice between read_sql, read_sql_query and read_sql_table. Lets start with the table.

The schema (defaults to dbo) and columns (defaults to all columns) parameters are optional. There are quite a few other parameters. Have a looking at the documentation.
To load results from a SQL query is only slightly more complex. We will make use of the multi-line string again for readability and maintenance.
Connecting to Azure SQL DB
Hopefully by now you realize the benefits of using Azure SQL DB. Our company uses Azure SQL DB as a data management solution for Power BI. Yes, there is huge benefit in persisting and managing your data outside of Power BI! Perhaps I’ll cover this Power BI solution architecture in a future post. (hint … have a look at dataframe.to_sql)
Azure SQL DB makes use of the latest SQL Drivers. SQL Alchemy will moan if you try to adapt the connection string we have above which uses the standard SQL driver. Also note the additional settings such as encryption and trust certificates.
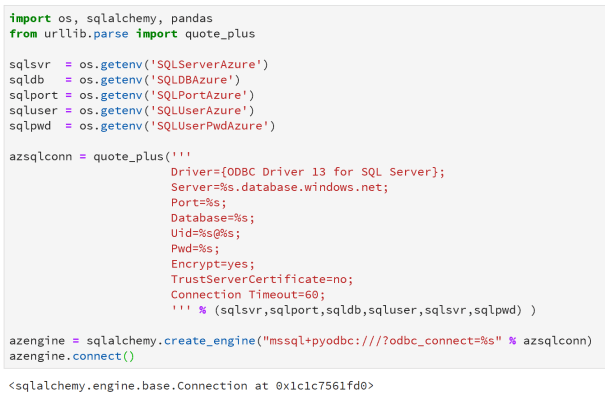
The rest works the same as the local SQL instance once you have created the engine.
Conclusion
By now you know that once your data is in a dataframe, The Python script in the Power Query editor will recognize your data.
Of course it is much easier to do this in Power Query without a line of code. But you may have scenarios where you perform data cleansing, transformations, combining, transposing, etc on the dataframe before loading your data into Power BI.
The key idea that drew my interest in the first place was the ability to re-use code across platforms and applications.
SQLSaturday #793 Cape Town
I’ll be speaking about Python integration in Power BI at SQLSaturday #793 Cape Town this coming Saturday, 8 September. If you are in Cape Town, come and join us. There are many great sessions to pick from.

Such a great blog. Thanks for this, it will be very useful as Microsoft integrates more and more with Python, R and other languages. Looking forward to the next post.
[…] may want to revisit the post on SQL Server connectivity. The last line of code is all that’s […]