
The previous post might have left you feeling that its a bit too complicated and a bit too abstract. Dont worry, the concepts will be clearer after a bit of a visual recap and then exploring how we would navigate the JSON/dictionary structures and finally how we reconstruct a “flattened” dictionary from the original dictionary.
Visual recap
We discussed that the JSON format is the same as a Python dictionary i.e. it consists of key: value pairs separated by a comma and enclosed inside braces. The keys are just names and the values may be of type string, number, boolean, list or dictionary (object).
The image below is the JSON file we created in the previous post. It is a list of 3 dictionaries. Each dictionary has the same keys, but the values may differ. We access the values by referencing the keys.
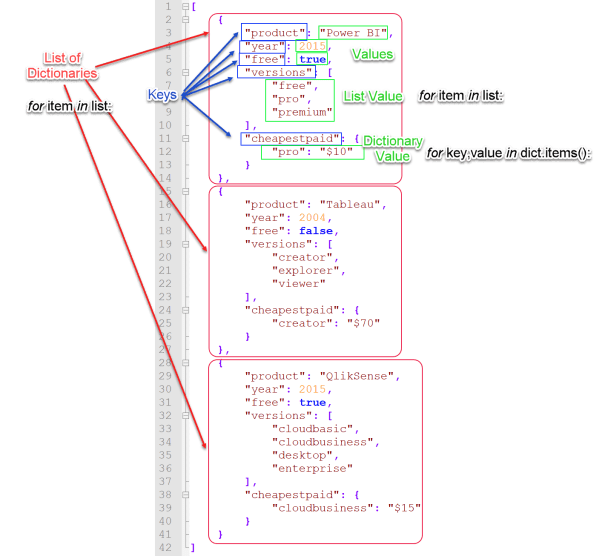
Navigating the JSON file
We can iterate through the JSON file using the for loop structure. Lets start by loading the JSON file and then looping through the outer list of dictionary items. Our image above shows that there are 3 dictionary items. We will observe the same from the code below.
import json
with open('d:\\data\\json\\data.json') as json_file:
mydict = json.load(json_file)
#looping through each object in the list
for obj in mydict:
print(obj)

In order to traverse the key: value pairs inside each dictionary, the for loop structure is slightly different. We will nest the dictionary for loop inside the list for loop so that we can access the key: value pairs for each of the 3 dictionaries.
for obj in mydict:
for key, value in obj.items():
print(mydict.index(obj), key, value)
For good measure, we have added in the index of the list item so that we know which dictionary the key: value pairs are associated with.

We know from the file structure that we still have list and dictionary values to deal with. We will choose our for loop structure according to the value type (list or dictionary). In order to get the values out of the “versions” list, we will use the list for loop structure nested inside our existing nested loop structure.
for obj in mydict:
for key, value in obj.items():
if type(value) == list:
for item in value:
print(mydict.index(obj), obj['product'], key, item)
Note how we test if the value type is a list. We are excluding all other key values.

To keep the data meaningful we have retained the dictionary index and product value that are associated with the list items.
We can use the same technique with the nested dictionary, by using the dictionary for loop structure.
for obj in mydict:
for key, value in obj.items():
if type(value) == dict:
for key2, value2 in value.items():
print(mydict.index(obj), obj['product'], key2, value2)

At this stage we have everything we need in terms of navigating the dictionary. We know the difference in for loop structure for lists vs dictionaries. We also know how to test the data type of the dictionary value and we know how to reference the keys, values and indexes.
Reconstructing the dictionary
To create a flattened dictionary (no list or dictionary values), we will use a combination of navigation techniques just shown. The only additional techniques required are a bit of list and dictionary comprehension i.e. how to create and update a dictionary, and appending items to a list.
We create empty lists and dictionaries in the same way, but we append to these data structures in a different way.

We will now use the above in conjunction with our nested looping structures to create a flattened dictionary.
The principle of the technique is to isolate every key: value pair, including unpacking list or dictionary values. Each unpacked key: value pair is then added to a new dictionary that no longer has list of dictionary values. Finally we append each dictionary to create a new list of dictionaries, and the resulting dictionary list is added to a dataframe.
import json, pandas
with open('d:\\data\\json\\data.json') as json_file:
mydict = json.load(json_file)
dict_lst = [] #initialise and empty list to hold the final result
#outer loop through each dictionary
for obj in mydict:
flat_dict = {} #initilaise a target dictionary
#loop through each key: value pair in dictionary
for key, value in obj.items():
#test the data type of each value
#handle list and dictionary types in the respective ways
if type(value) == dict:
for key2, value2 in value.items():
#use both the original key and value as values in new dict
flat_dict.update({'cheapest':key2, 'price':value2})
elif type(value) == list:
for item in value:
#create a key of values version0, version1, version2, etc
flat_dict.update({'version' + str(value.index(item)): item})
else:
flat_dict.update({key: value})
#append the flattened dictionary to our new dictionary list
dict_lst.append(flat_dict)
#add the dictionary list to a dataframe
df = pandas.DataFrame.from_dict(dict_lst)

This technique has greater flexibility in terms of allowing other ways of manipulating the dictionary. Ironically it also appears easier than the technique shown in the previous post where we used dataframes. Best of all, this technique forces a level of understanding of dictionary data structures.
In part 3 of the JSON series I want to explore a real world example that include JSON with a metadata section and retrieving data from an API.

Wow! this is super helpful in flattening JSON structures. Thanks once again for taking the time to share. I’m looking forward to the next blog post.
[…] appropriate techniques to handle the JSON data. Most of these techniques were covered in part 1 and part 2 of this […]