
This is part 3 of the introduction to handling JSON with Python. This post covers a real world example that accesses data from public API from the New York City Open Data. For fun we are going to look at the most popular baby names by sex and ethnicity.
The key idea is that JSON structures vary, and the first step in dealing with JSON is understanding the structure. Once we understand the structure, we select the appropriate techniques to handle the JSON data. Most of these techniques were covered in part 1 and part 2 of this series.
Browsing the data
You can browse the data from the API URL endpoint. The displayed format is not really going to help us understand the data. Copy the text over to an online JSON formatter such as jsonformatter. Here we see the pretty JSON format on the left:

Click on the JSON Viewer button to see a tree view of the JSON data on the right:
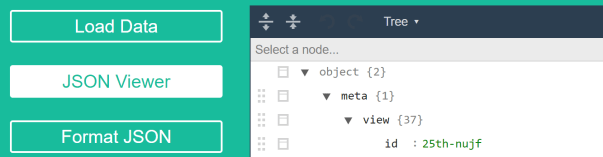
The very first thing you notice right at the top of the tree view is that there are 2 objects at the top level and the JSON consists of nested dictionaries. By collapsing the tree structure to only the top level, we see the following:

Here we see the meta dictionary has 1 sub-dictionary and the data dictionary is a list of 11345 items. Further exploration shows that the data dictionary items are also lists i.e. the data dictionary is a list of 11345 lists (rows). Each of these lists are a list of 14 items. Each item represents a value (column).

The data we have only shows a list index and a list value. We don’t know what those values represent … yet.
Loading the data
It is reasonably easy to get to the data by referencing the data dictionary directly as shown in the script below:
import requests, pandas url = 'https://data.cityofnewyork.us/api/views/25th-nujf/rows.json?accessType=DOWNLOAD' req = requests.get(url) mydict = req.json() df = pandas.DataFrame.from_dict(mydict['data'])
The results show that the only problem is the column names are the index values.

Loading the column meta data
We revisit our JSON tree view and find that the meta dictionary contains a view sub-dictionary, which in turn contains a list of dictionaries called columns. Each item in the columns list is a dictionary with 8 column properties.

To access the column names is not that tricky. We will use the same techniques from the previous posts. Perhaps the only “trick” is to reference the nested columns dictionary. The rest of the code accesses the key: value pairs nested inside the list, and adds the column name value to our columns list. The final step replaces the column headers with the newly acquired column headers.
cols_lst = []
for obj in mydict['meta']['view']['columns']:
for key, value in obj.items():
if key == 'name': cols_lst.append(value)
df.columns = cols_lst
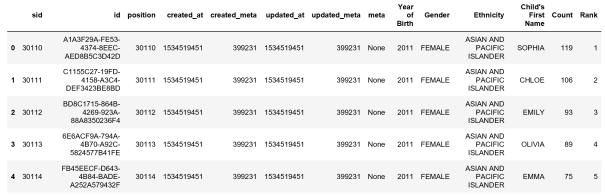
You can clean up by removing the columns you don’t need (see previous blog posts using the drop method for dataframes).
When the problem is understood …
… the solution is (hopefully) obvious. While this post barely introduced anything new from a Python perspective (except referencing sub-dictionaries), the focus was on understanding the problem and cementing techniques for handling JSON.
In the next blog post I want to conclude this JSON series with another real world example.

Leave a comment