
This is another post based on a demo from my SQLSaturday session about Python integration in Power BI. The data file is also available from this link or download your own file from the Reserve Bank link below.
It is a pattern I use fairly often because flat files lend itself to the artistic license of the data provider i.e. they can do just about anything they want with the flat file.
Lets take a look at a real world example. The South African Reserve Bank provides daily exchange rate data (ZAR per USD) through an embedded Reporting Services environment. When you download the data as Comma Separated Value (CSV), this is what you get:
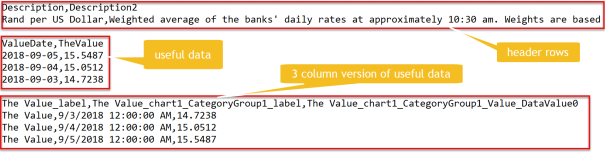
The data represents 3 days of data. We only require the section indicated as “useful data”. If you look at the file structure carefully, you will notice that it could still be treated as a CSV file. When you open the file with the Query Editor, you will see that Power BI already treats the file like a CSV (or an Excel file that does not have all cells populated).
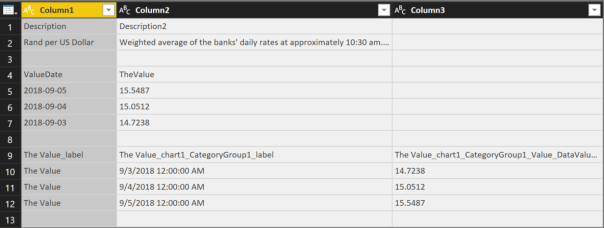
I am going to illustrate two methods of dealing with this in Python. You may encounter scenarios where either one could be useful.
Method 1: Treat the file as CSV
This method will essentially mimic what the Power BI Query Editor does with the file. We will use the Pandas read_csv method, but we will use some parameters to handle our requirements. Without indicating that there are three columns, read_csv will throw an exception when it encounters a third field further down the file. To indicate three columns we simply specify the columns.
import pandas
df = pandas.read_csv('D:\\data\\dirty\\ExchangeRateDetail.csv',
skiprows=4,
names =['Date','Value','Extra'])
You will notice that we have ignored the first four rows that we don’t need.

From this point on its a simple process that we have encountered in previous posts. We are going to do three things to get the file into a ready to use state:
- Drop the extra column
- Remove (filter) unwanted rows
- Explicitly cast the data types
import pandas
df = pandas.read_csv('D:\\data\\dirty\\ExchangeRateDetail.csv',
skiprows=4,
names =['Date','Value','Extra'])
df = df.drop(['Extra'], axis=1) # drop "Extra" column
df = df[df.Date != 'The Value'] # filter rows
df = df[df.Date != 'The Value_label'] # filter rows
df['Date'] = pandas.to_datetime(df['Date']) # explicit data type cast
df['Value'] = pandas.to_numeric(df['Value']) # explicit data type cast
The final output can now be used as a Python data source in Power BI

Method 2: Read the file line by line
In this example we will read the data line by line. Each line will get add to a list i.e. we will end up with a list of lines. We will then use some list comprehension techniques filter the data before adding it to a dataframe.
with open('D:\\data\\dirty\\ExchangeRateDetail.csv') as f:
lines = [line for line in f]
The new line characters form part of the line as shown below in our list where each item is a line in the file.

There are also special characters at the start of the file, but we dont need to worry about this as we will not use this item in the list.
To strip off the “\n” we will use the rstrip method which removes characters from the right hand side of a string. By not specifying a character, whitespace characters are removed. This includes “\n”.
with open('D:\\data\\dirty\\ExchangeRateDetail.csv') as f:
lines = [line.rstrip() for line in f]

With the newline removed, we can now start filtering the list of items(lines). We start by filtering out the empty items (blank lines).
lines = list(filter(None, lines))

Next we remove the first 3 items, but keep the rest of the list.
lines = lines[3:]

Our final filter condition is to remove all items that start with “The”
lines = [t for t in lines if not t.startswith('The')]
![]()
Now our list is ready to convert to a dataframe.
import pandas df = pandas.DataFrame(lines)

Note that we end up with a single column (0) dataframe. Our final steps to get the dataframe into a ready to use state are:
- split the column on comma separator
- drop the original column
- Explicitly cast the data types
Lets put a complete final script together that include the final steps.
import pandas
with open('D:\\data\\dirty\\ExchangeRateDetail.csv') as f:
lines = [line.rstrip() for line in f]
lines = list(filter(None, lines)) # drop blank lines
lines = lines[3:] # remove top rows
lines = [t for t in lines if not t.startswith('The')] # remove rows starting with "The"
df = pandas.DataFrame(lines) # add remaining rows to a dataframe
df['Date'] = pandas.to_datetime(df[0].str.split(',').str.get(0)) # split of the Date column
df['Value'] = df[0].str.split(',').str.get(1) # split off the value column
df = df.drop([0], axis=1) # drop the original column (0)
df['Date'] = pandas.to_datetime(df['Date']) # explicit data type cast
df['Value'] = pandas.to_numeric(df['Value']) # explicit data type cast
The final result is the same as method 1.
Hopefully that provides some ideas on how to deal with flat files in general. As mentioned at the start of this post, it is often challenging to deal with flat files as it is up to the data provider to produce a well structured file.

Leave a comment