
In modern application environments we will encounter JSON (JavaScript Object Notation) as the preferred file format for data-interchange. Many APIs and files are delivered in JSON format. Working with JSON format could potentially be challenging, especially if you are new to it. It is easy to get thrown by values that are variable length lists or values that are dictionaries (nested objects). So the three key things I want to cover in this post are:
- The basics of the JSON and how it compares to a Python dictionary
- Dealing with values that are lists (including variable length lists)
- Dealing with nested objects (including where keys differ)
There will potentially be many opportunities to improve the code. Please let me know or comment so that I can learn in the process.
The JSON format is best understood by comparing it to a Python dictionary. Be aware though that the JSON format (rules for data representation in text format) only appears similar to the Python dictionary (a data type that supports add, delete, sort, etc).
Python dictionaries
Dictionaries consist of key: value pairs separated by a comma and enclosed inside braces. The value may be of type string, number, boolean, list or object (dictionary).
string_dict = {"product": "Power BI"}
number_dict = {"year": 2015}
boolean_dict = {"free": True}
array_dict = {"paid": ["pro", "premium"]}
object_dict = {"price": {"pro": "$10"} }
mydict = {"product": "Power BI",
"year": 2015,
"free": True,
"paid": ["pro", "premium"],
"cheapest": {"pro": "$10"}}
To access the values we reference the keys:

Note how the second example combines a key with a list index, and the third example combines the key for the outer object with the key of the nested object.
List of dictionaries
We can also create an array (list) of dictionaries:
dict_array = [
{"product": "Power BI",
"year": 2015,
"free": True,
"versions": ["free",
"pro",
"premium"],
"cheapestpaid": {"pro": "$10"}},
{"product": "Tableau",
"year": 2004,
"free": False,
"versions": ["creator",
"explorer",
"viewer"],
"cheapestpaid": {"creator": "$70"}},
{"product": "QlikSense",
"year": 2015,
"free": True,
"versions": ["cloudbasic",
"cloudbusiness",
"desktop",
"enterprise"],
"cheapestpaid": {"cloudbusiness": "$15"}}
]
We can reference a specific array item by its index, then the dictionary key as follows:
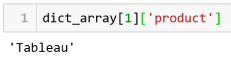
Here the list index precedes the dictionary key. Remember that the list index offset is 0.
Creating a JSON file from a dictionary
First we convert the dictionary to a JSON string using the built in json package. The json.dumps function converts a dictionary into JSON encoded format. Add the following to the code above:
import json print(dict_array) json.dumps(dict_array)
Compare the output of the dictionary and the JSON encoded string. The appearance is almost identical. The dictionary displays the key/value pairs in single quotes, while the JSON string displays the key/value pairs in double quotes and the entire string in single quotes.

Now we can write the JSON string to a file. Here we use json.dump (without the s) which allows us to write the file rather than a unicode string.
with open('d:\\data\\json\\data.json', 'w') as outfile:
json.dump(dict_array, outfile, indent=4)
The indent=4 parameter produces a pretty json layout i.e. human readable format.
Load the JSON file
In the same manner that we wrote the JSON file, we can read the file using the json.load function. At this point the file content is loaded as a list of dictionaries.
with open('d:\\data\\json\\data.json') as json_file:
dict_lst = json.load(json_file)
Adding the dictionary to a dataframe
import pandas df = pandas.DataFrame.from_dict(dict_lst)
From the output we can see that we still need to unpack the list and dictionary columns.

One of the methods provided by Pandas is json_normalize. This works well for nested columns with the same keys … but not so well for our case where the keys differ.
The dictionary you wish you got
Here is a simple example where the keys are the same:
mydict = [{"company": "ABC",
"location": {"province": "Gauteng",
"city": "Sandton" }},
{"company": "XYZ",
"location": {"province": "Western Cape",
"city": "Cape Town" }}]
import pandas
pandas.DataFrame.from_dict(mydict)
from pandas.io.json import json_normalize
json_normalize(mydict)

Back to the real world
In our example, our keys dont match across dictionaries, so the result is not great.
from pandas.io.json import json_normalize json_normalize(dict_lst)

Because the keys differ they are split across different columns. Also the list column is not handled. Lets use a different technique to handle the list column. Pandas apply allows us to apply operations across dataframes (rows/columns). Here we use Pandas Series to create a column for each list item.
import pandas df = pandas.DataFrame.from_dict(dict_lst) df2 = df['versions'].apply(pandas.Series)

The resulting dataframe can be concatenated with the existing one as follows:
df3 = pandas.concat([df[:], df2[:]], axis=1)

So we still have to deal with the dictionary column. We will use dataframe methods (melt, merge, drop) that were covered in previous posts, along with some new methods. I’ve taken a different approach here by providing all the steps with comments and then a visual that shows the output at each step.
import pandas df = pandas.DataFrame.from_dict(dict_lst) #split the versions list column into individual columns df1 = df['versions'].apply(pandas.Series) #concatenate the original dataframe with the individual version columns df2 = pandas.concat([df[:], df1[:]], axis=1) #split the dictionary column into individual columns df3 = pandas.DataFrame(df2['cheapestpaid'].values.tolist(), index=df2.index) #add the product column (to create a lookup column) df4 = pandas.concat([df['product'], df3[:]], axis=1) #melt (unpivot) the value columns df5 = pandas.melt(df4, id_vars=['product'], value_vars=['cloudbusiness','creator','pro'], var_name='cheapest') #drop NaN values to finalise the lookup table df6 = df5.dropna() #merge with the lookup table df7 = pandas.merge(df2, df6, on='product', how='outer') #drop unwanted columns df8 = df7.drop(['cheapestpaid','versions'], axis=1)

So the result is not the simplest of code, however it is not that complex either. We solved the entire problem using Pandas. What I have not tested is how we would solve this without Python in Power BI (visual Query Editor or M). It would also be interesting to compare solution complexity. In my case, I already had these Python patterns, so it was a matter of script re-use.
In the next post I want to explore methods of traversing and reshaping the data without Pandas and dataframes. It will provide better understanding of the JSON format and expand on the possibilities with Python script.

[…] previous post might have left you feeling that its a bit too complicated and a bit too abstract. Dont worry, the […]
Great article once again. A quick side note: the reason we reference a List item by it’s position e.g. MyList[0] and a Dictionary item by it’s key e.g. myDict[‘Foo’] is that a List is an ordered collection of items (duplicates allowed) and a Dictionary is an unordered collection of items (with no duplicates allowed).
Looking forward to the next round; as always, thanks for sharing.
[…] Loading JSON … it looks simple … Part 1 (@ToufiqAbrahams) […]
[…] select the appropriate techniques to handle the JSON data. Most of these techniques were covered in part 1 and part 2 of this […]